
Was können wir gegen Fake News tun? Und wie können wir “kreative” Neuschöpfungen von KI erkennen? Wie also können wir künftig “wahre” von “unwahren” Fakten unterscheiden?
Ein Ansatz könnte das Semantic Web sein. Oder konkreter: Der Kontext eines Content-Stücks, der uns verlässlich sagt: Dieses Bild von der Mona Lisa ist vertrauenswürdig, denn es ist nicht manipuliert; genau so hängt das Original im Louvre. Oder: Ja, dieses Fußballergebnis stimmt, 50.000 Zuschauer:innen waren letzte Woche im Stadion und haben das Spiel verfolgt. Woher wissen wir das? Weil wir die Quelle(n) kennen.
Wenn wir User:innen bei jedem einzelnen Inhalt verlässlich wissen würden, aus welcher Quelle dieser Inhalt stammt und in welchem Zusammenhang er entstanden ist, wäre das ein erster Schritt. Auch die Suchmaschinen könnten diese Unterscheidung machen und so “echte” von “gefälschten” oder “KI-erzeugten” Inhalten trennen.
Das wäre kein Hexenwerk, es wäre nur ein wenig aufwändig für die Content-Ersteller:innen. Technisch ist es ein relativ alter Hut. Es wäre genau das, was Google den Knowledge Graph nennt und den alle relevanten Suchmaschinen auslesen können. Ich habe darüber ja schon an unterschiedlichen Stellen geschrieben: Beispielsweise wäre es sehr schwierig bis nahezu unmöglich, den Satz “Der Mond ist aus Käse” sinnvoll in diesen Knowledge Graph einzupassen; kein anderer Mond im bekannten Universum ist aus Käse, und im semantischen Web würde dieser Satz also sofort als “unwahr” auffallen.
Um also Fake News in einem ersten Schritt von verlässlicheren Inhalten unterscheidbar zu machen, bräuchten wir ein Etikett, das wir an alle Inhalte heften könnten. Ein Etikett, das den Inhalt mit klar festgelegten Begriffen beschreibt: Wo kommst Du her, wer hat Dich wann wo erstellt, warum gibt es Dich, in welcher Beziehung stehst Du mit anderen ähnlichen Inhalten, etc.
Wenn bspw. eine Behörde einen Datensatz öffentlich ins Netz stellt, könnte ein erster Qualitätshinweis also genau dieser Hinweis auf die Behörde sein: Es handelt sich schon mal nicht um KI 😉
Spaß beiseite: Je mehr Informationen wir zum Kontext eines Content-Stücks erhalten, desto eher können wir eine Einschätzung über die “Echtheit” und damit die “Wahrheit” dieses Content-Stücks abgeben. Und die Suchmaschine, die uns den Content anbietet, eben auch.
Das Schema gegen Fake News?
Mein Diskussionsbeitrag zur Frage: Wie kann das Internet durch seine eigene Architektur Fake News unterdrücken – ohne Zensur, ohne direkten redaktionellen Eingriff, sondern durch den Netzwerkeffekt selbst? Kann das funktionieren?
Seltsamer- und ärgerlicherweise wissen viel zu viele Behörden und Verwaltungen nicht von dieser einfachen Möglichkeit, aktiv an einem “wahreren” Netz zu arbeiten. Oder nutzen sie nicht. Städte beispielsweise haben fast ausschließlich valide Informationen – sie markieren sie aber nicht für die Suchmaschinen und damit “für uns”.
Ich habe dazu einmal beispielhaft die Webstartseiten der 25 größten deutschen Städte durch den Schema-Markup-Validator checken lassen.
Was die beiden Großstädte am Rhein Karlsruhe.de und Koeln.de wirklich vorbildlich umsetzen, ist bei den allermeisten anderen Kommunen der Top-25 “Neuland” – ärgerlicherweise auch bei der Website, für die ich jahrelang als Redakteur arbeiten durfte und die einen zehn Jahre langen Relaunch-Prozess hinter sich hat: Frankfurt.de. Dort findet sich – zumindest auf der Startseite – kein erkennbares Schema Markup.
Bonn, Wuppertal, Duisburg und Stuttgart haben immerhin ihre Linkstruktur hinterlegt, was zeigt, dass sie grundsätzlich das Prinzip verstanden haben (wenngleich ich unterstelle, dass es sich hierbei wohl schlicht um SEO-Maßnahmen handelt). München, Dresden und Bielefeld sagen den Suchmaschinen, dass es sich um eine Website einer Stadt handelt – auch das ist ein erster wichtiger Schritt. Beim Rest: Fehlanzeige. Die Bundes- und Landeshauptstadt Berlin, die ihr eigenes Bundesland ist: nix. Die Bundesländer Hamburg und Bremen: nix. Die Landeshauptstädte Wiesbaden, Hannover, Düsseldorf – auch nix. (Auf der Startseite, wohlgemerkt… Auf Artikelebene gibt es bei hamburg.de hin und wieder doch einen Eintrag – aber auch hier hat er eher SEO-Gründe.)
| Berlin | 3.677.472 | www.berlin.de | Keine Elemente erkannt |
| Hamburg | 1.853.935 | www.hamburg.de | Keine Elemente erkannt |
| München | 1.487.708 | www.muenchen.de | Type: WebSite |
| Köln | 1.073.096 | www.koeln.de | VORBILDLICH! |
| Frankfurt am Main | 759.224 | www.frankfurt.de | Keine Elemente erkannt |
| Stuttgart | 626.275 | www.stuttgart.de | Type: BreadCrumbList |
| Düsseldorf | 619.477 | www.duesseldorf.de | Keine Elemente erkannt |
| Leipzig | 601.866 | www.leipzig.de | Keine Elemente erkannt |
| Dortmund | 586.852 | www.dortmund.de | Keine Elemente erkannt |
| Essen | 579.432 | www.essen.de | Keine Elemente erkannt |
| Bremen | 563.290 | www.bremen.de | Keine Elemente erkannt |
| Dresden | 555.351 | www.dresden.de | Type: WebPage |
| Hannover | 535.932 | www.hannover.de | Keine Elemente erkannt |
| Nürnberg | 510.632 | www.nuernberg.de | Keine Elemente erkannt |
| Duisburg | 495.152 | www.duisburg.de | Type: BreadCrumbList |
| Bochum | 363.441 | www.bochum.de | Keine Elemente erkannt |
| Wuppertal | 354.572 | www.wuppertal.de | Type: BreadCrumbList |
| Bielefeld | 334.002 | www.bielefeld.de | Type: WebPage |
| Bonn | 331.885 | www.bonn.de | Type: BreadCrumbList |
| Münster | 317.713 | www.muenster.de | Keine Elemente erkannt |
| Mannheim | 311.831 | www.mannheim.de | Keine Elemente erkannt |
| Karlsruhe | 306.502 | www.karlsruhe.de | VORBILDLICH! |
| Augsburg | 296.478 | www.augsburg.de | Keine Elemente erkannt |
| Wiesbaden | 278.950 | www.wiesbaden.de | Keine Elemente erkannt |
| Mönchengladbach | 261.001 | www.moenchengladbach.de | Keine Elemente erkannt |
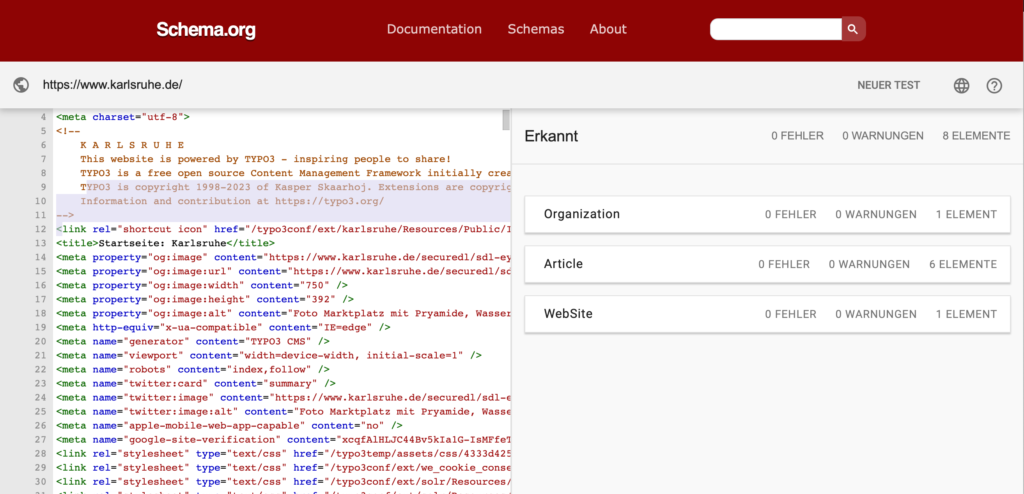
Dabei wäre es so einfach umzusetzen, dass jedes zehnjährige Kind, das lesen kann (und Englisch), den Code versteht. Nehmen wir als Beispiel eine zufällige Unterseite von Karlsruhe.de – eine Landingpage mit Teasern zu anderen Artikeln. Aus dem Code des Web-CMS heraus wird jeder einzelne Artikel mit Schema-Markup etikettiert; hier etwas sparsam, aber ausreichend. Alleine diese drei Zeilen Typ, Veröffentlichungsdatum und Titel reichen den Suchmaschinen schon, um sie mit der Stadt Karlsruhe in Verbindung zu bringen.
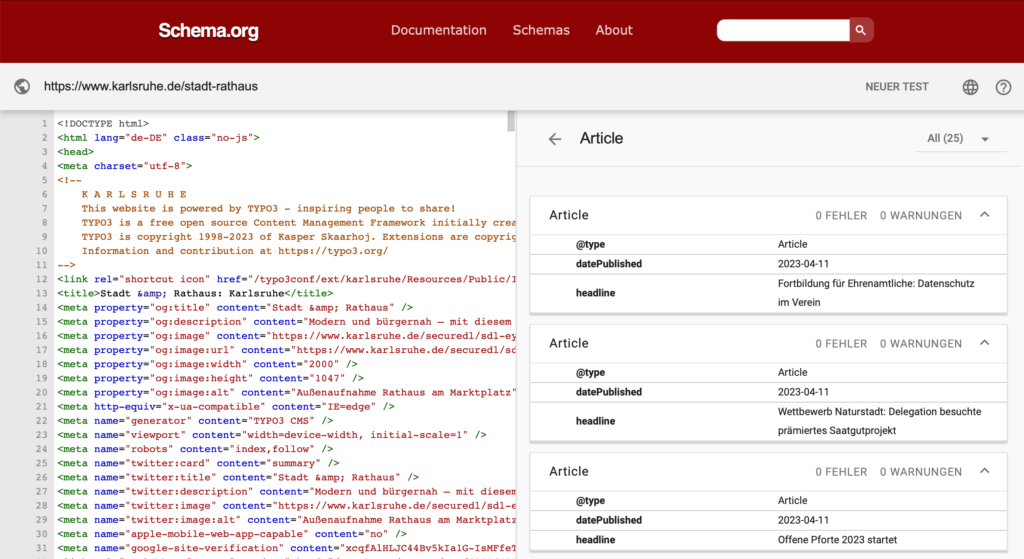
Wie heißt der Oberbürgermeister? Und in welchem Verhältnis steht er zur Stadt – eine banale Frage für Menschen, aber für das semantische Web entscheidend. Auf der Unterseite, die auf Karlsruhe.de den Oberbürgermeister vorstellt, stehen alle Daten, klar. Aber für die Suchmaschinen wird erst durch den speziellen Schema-Eintrag klar, dass es sich bei Dr. Frank Mentrup a) um eine echte Person handelt, die b) ihren Arbeitsplatz im Rathaus am Marktplatz in Karlsruhe hat. Damit sind die Stadt Karlsruhe, die Person Dr. Frankfurt Mentrup und das Karlsruher Rathaus miteinander verknüpft – und zwar maschinenlesbar und weltweit einheitlich strukturiert! Alle großen Suchmaschinen stellen nun denselben Kontext her – und Karlsruhe stellt der Welt und dem Internet damit verlässliche, verarbeitbare, nutzbare und absendergeprüfte Fakten zur verfügung. Eine einfache Seite: “Das ist unser OB!” mit einem Foto und einem Namen hätte nicht dieselbe funktionale Wirkung, sie bliebe für die Suchmaschinen ein zufälliges Contentstück.
Treiben wir dieses Prinzip nun einmal weiter und füllen das Schema-Markup einmal für den neuen Frankfurter Oberbürgermeister Mike Josef aus.
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Person",
"name": "Mike Josef",
"url": "https://frankfurt.de/service-und-rathaus/stadtpolitik/magistrat/oberbuergermeister",
"image": "https://frankfurt.de/-/media/frankfurtde/personen/magistrat/image/mike-josef/mike-josef-quer.ashx",
"sameAs": [
"https://www.instagram.com/mikejoseffm/",
"https://www.facebook.com/mikejosefffm/"
],
"jobTitle": "Oberbürgermeister",
"worksFor": {
"@type": "Organization",
"name": "Stadt Frankfurt am Main"
}
}
</script>Dieses JSON-Script hat viele Vorteile: Seine Struktur ist weltweit einheitlich definiert – die Inhalte sind aber trotzdem flexibel auf die Situation anpassbar. Maschinen können sie problemlos lesen – und wir Menschen auch. Mit dieser Form der strukturierten Daten können die Webseitenbetreiber selbst bestimmen, welche Informationen sie für das semantische Web bereitstellen. Und: Mit dieser Form können sehr gut Kontexte, Abhängigkeiten, Hierarchien, Verknüpfungen abgebildet werden. Und diese Verknüpfungen, dieser Kontext ist es, der den Inhalt eineindeutig macht. Der also dafür sorgt, dass wir über Mike Josef, den gewählten Oberbürgermeister von Frankfurt sprechen – und nicht etwa von einem anderen Mike Josef.
Damit schaffen Webseitenbetreiber also folgendes:
- Ihr Inhalt wird mit Informationen angereichert, die Maschinen weiterverarbeiten können
- Ihr Inhalt wird in einen Zusammenhang mit anderen Inhalten gebracht.
- Durch diese Beschreibungen wird ein Kontext hergestellt, der den Inhalt eindeutig bestimmt.
- Und dadurch haben Fake News weniger Chancen – weil ihnen dieser Kontext fehlt.
Die Aufgabe, die ich also sehe – und bei der ich sehr gerne mithelfe – ist: Liebe Behörden, Verwaltungen und öffentliche Einrichtungen, lasst uns unsere Inhalte für “das Internet” kontextualisieren. Denn nur dann haben Suchmaschinen und damit wir selbst eine Chance, “öffentliche Inhalte” mit einem gewissen Qualitätsversprechen von reinen Erfindungen und Lügen zu unterscheiden. Wir sollten das schnell angehen. Es ist einfacher als Ihr vielleicht befürchtet.